
| Copyright 1996-2001 by Donald R. Tveter, commercial use is prohibited. Short quotations are permitted if proper attribution is given. This material CAN be posted elsewhere on the net if the posted files are not altered in any way but please let me know where it is posted. The main location is: http://dontveter.com/bpr/bpr.html |
Fast training is great but ultimately you want the best possible results on a test set. This section is dedicated to that goal. The possible options here are:
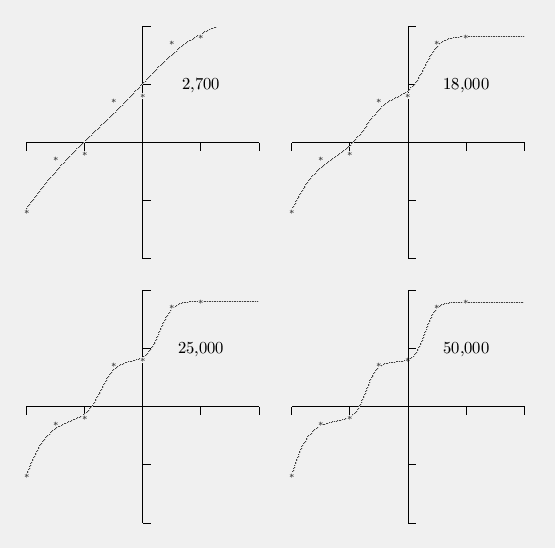
One of the virtues of backprop is that it will fit any function even if you don't know the form of the function you need to fit. But its also a curse because it can lead to overfitting, as training goes on the network will end up fitting the training set data very closely while ruining the results on the test set, thus you must be careful to train until the test set results hit a minimum and then stop. (Sad to say but you don't always know when the test set has hit the minimum where you should stop, sometimes you hit a local minimum even in this process.) The following figure indicates the problem of trying to fit the line y = x + 1. The points marked with an asterisk are training set points set just above and below the exact line, this is typical of real world measurements, the deviation from the ideal is said to be the result of noise in the data.
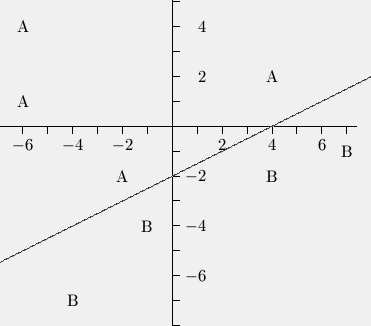
In a pattern classification problem there is no guarantee that your backprop network is going to come up with a sensible way to partition the boundaries between classes. The following is a particular 2D example I cooked up for my book. First I needed an example of some linearly separable points so I made up 4 examples from each class, they are marked with an A or a B in the following plot and there is a straight line separating the two classes:
Then I needed an example of a non-linearly separable set of points so I added 2 more from each class and drew a curve to separate them:
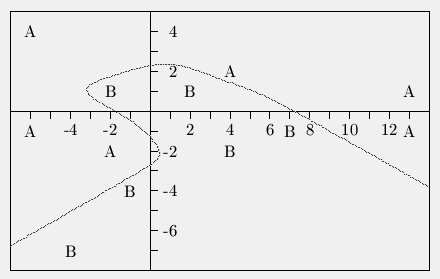
Then I proceeded to test backprop networks to see how they divided up the space, here are the results from three of them:
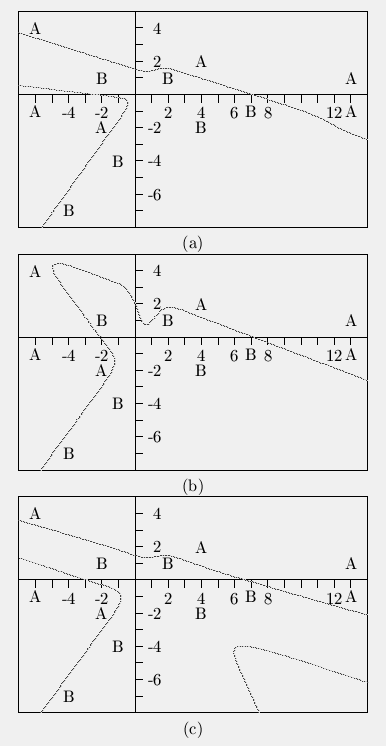
In most cases the training resulted in networks like the first one. (Exercise: What assumptions did I make about the data when I did the hand-drawn curve that the network did not make?) Sometimes it came up with stranger solutions like the second and third ones. Notice how in the third case the network made a portion of the space on the lower right part of class A despite the fact that there are no members of class A nearby.
Odd generalization like this can be minimized somewhat by averaging results over a number of networks. I think that the experiment also suggests that a reasonable cross-check is to do a nearest neighbor analysis of each unknown pattern as well, if your unknown point is not pretty close to a point from the same class then the answer from the network is suspect.
The topic of generalization is also covered on the page: Exact Representations from Feed-Forward Neural Networks
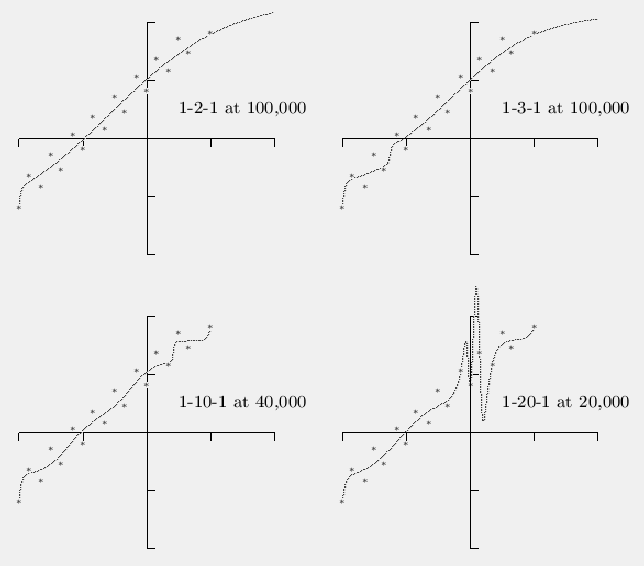
It is widely stated that you will get the best results on the test set with a relatively small number of hidden units. In fact one rule is that you need at least as many training set patterns as there are weights in the network. On the other hand there are reports that in certain cases networks with many more weights than patterns also work well. For results and discussion that support this later position see the online paper by Lawrence, Giles and Tsoi.
One of the techniques used to improve results is to combine estimators (network outputs) of many networks the equivalent of getting the opinions of many experts. Imagine the solution to your problem is just a straight line. A network is unlikely to find that straight line, it will find a curvy line near the straight line. Probably another network will find a different curvy line near the straight line. If you average a number of such results the curves may tend to cancel out and you will get something closer to the straight line. The farthest I've gotten in experiments along these lines is to simply average the output units of several networks, sometimes it works but sometimes it doesn't. These papers also show that giving the results from one network a higher weight than from another network also helps. A fairly easy to follow (as these things go) is the online paper by Perrone and Cooper. One of the advantages of these methods is that you may get very good results even with rather poorly trained networks.
For a collection of papers on the subject by Tirthankar RayChaudhuri (most of which I have never seen) there is his page at Marquarie University, Australia.
An additional technique is called bagging, see an online paper by Leo Breiman.
If you know the form of the function you are trying to fit you are better off using some standard statistics routine to do it. For example if you know the form of the function is linear you can do a simple least squares analysis and find the answer faster (and maybe more accurately) than by using backprop. With backprop the network does not know the form of the function and it will take the opportunity (if allowed) to overfit the function. That is, if you are trying to fit a straight line for instance, if the points are scattered above and below the line the network may come up with a curvy line that passes very close to each of the points. One way to avoid this is to use the smallest possible number of hidden layer units. Another way is to use weight decay, a method that tries to keep the weights small. The idea is to subtract a tiny fraction from each weight at every pass through the network. If the weight is w and the tiny fraction is lambda * w, you use:
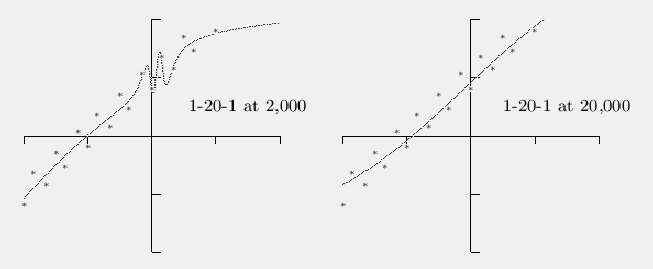
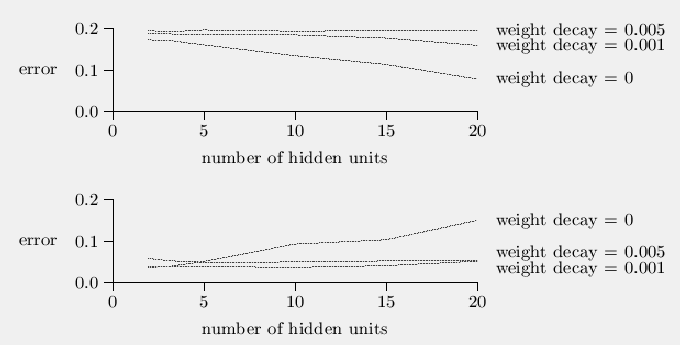
Some experiments by Finnoff, Hergert and Zimmermann show that the best results come from starting weight decay when the network reaches a minimum on the training set.
Note that acceleration algorithms like quickprop and rprop are not only faster they often get you a tighter fit than plain backprop. See the Better Algorithms entry.
Another method to improve results is to prune away excess weights. The article by Utans and Moody gives some results on an actual problem.
Another method to improve results is to prune away excess hidden layer units. Unfortunately there are a lot of them and I've never tried to program any of them.