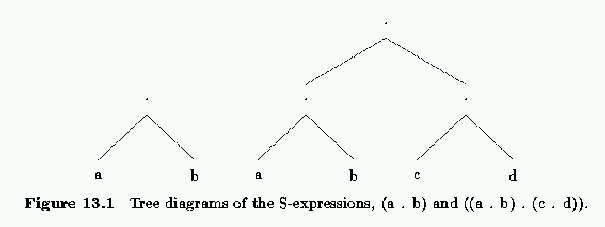
| Copyright 1995, 1999 by Donald R. Tveter |
| http://www.dontveter.com drt@christianliving.net, don@dontveter.com |
| Commercial Use Prohibited |
LISP is short for ``LISt Processing language" and it is one of the earliest programming languages developed. It was originally designed merely as a useful notation by McCarthy but one of his students realized it could be useful as a programming language and went on to produce the first LISP interpreter. There are a great many versions of LISP available and all these LISPs have a great deal in common, yet there are many annoying variations. The examples we will look at here will be from versions 1.4 and 1.6 of XLISP. There is a whole series of XLISP systems produced by David Betz that he has put in the public domain. The more recent versions of XLISP are fairly close to a recent standard, called Common LISP. Like PROLOG, LISP is normally run in an interactive mode. The user types in expressions to be evaluated and the interpreter prints out the results. LISP does not have the pattern matching capability of PROLOG built into it so in section 13.5 we will show a simple pattern matching function that matches patterns and instantiates variables somewhat like PROLOG.
The LISP language consists of Symbolic-expressions , or
S-expressions for short. The basic building block is an
atom . Atoms consist of a string of letters and digits and most
special characters except for the following ones:
|
|
|
|
|
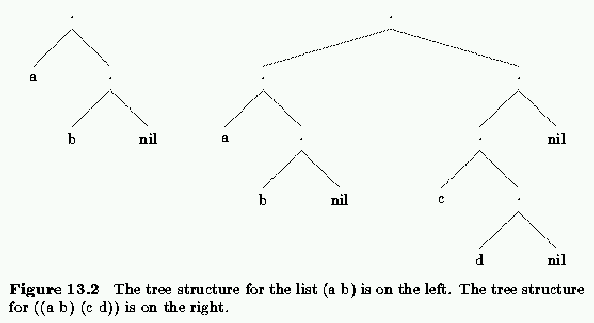
These general sorts of S-expressions are not used very often,
instead, there is a special sort of S-expression called a list
that is used almost all the time. A list containing the atoms, a and b
is written as:
|
|
This short description of S-expressions actually describes the whole syntax of the language. Everything in LISP consists of S-expressions, both the data and the program. For example, here is a simple function designed to find n!:
(defun fact (n)
(cond ((equal n 0) 1)
(t (* n (fact (- n 1))))))
The need to use lots of parentheses in forming functions should be
readily apparent. LISP was not designed to fit existing human pattern
recognition templates so it usually takes a while for people to build up
an inventory of pattern recognition templates that makes it possible to
easily write and understand LISP functions. One consequence of this
poor design is that users often manage to forget one or more parentheses
when writing down or typing in a LISP function1. Some LISP systems contain
special editors that aid in forming correct expressions. Some editors
have a LISP mode that can be helpful in matching parentheses up
correctly. It is virtually impossible to work with LISP unless the
system has some ``pretty-printing" capability that will neatly indent
expressions to make them readable.
We will now start looking at some of the simplest built-in functions. Some of the easiest functions to describe are the ones that do arithmetic. For instance, to add together two numbers such as 1 and 2, type in:
> (+ 1 2) 3In this sequence, > represents a prompt from the LISP interpreter. The interpreter immediately prints the answer 3 just below. The LISP interpreter regards the first item in a list as a function to evaluate and the remaining items are arguments that are usually evaluated2 before they are passed on to the function. When the arguments are numbers, the numbers naturally evaluate to themselves. The + function will actually allow an unlimited number of numbers to be added together in one step:
> (+ 1 2 3 4 5) 15Also an unlimited number of numbers can be multiplied together using the * function:
> (* 3 4 2) 24For - and /, only two operands are allowed:
> (/ 27 9) 3 > (- 88 100) -12The following call asks for the absolute value of -88:
> (abs -88) 88There are usually many other functions available in most versions of LISP to calculate special functions such as sin, cos, tan, log and so on.
LISP can also handle more complex expressions as well:
> (+ (* 2 3) (* 2 4)) 14
Of course, LISP has variables that can be assigned values and LISP has several functions to do this. The most commonly used one is setq. Setq evaluates its second argument but not its first so that it behaves just like an assignment statement in a normal language, like Pascal. Below are some examples of ``assignment statements" in LISP:
> (setq a 1) 1
> (setq b 2) 2
> (setq c (+ a b)) 3Notice that as a side-effect, LISP also prints out the value that was stored away. The last assignment statement gave c the value, 3. We can also check this out by typing in, simply, c and LISP will go look up the value:
> c 3Variables in LISP are created whenever they are needed and they become global variables, so the three assignments above created the global variables a, b and c as well as gave them values. Variables can also be declared inside functions and these variables vanish when the function call ends. Depending on the exact variety of LISP, it may or may not be possible to reference them from other functions. Any variable can take on any sort of value, an atom (numeric or symbolic), a dotted pair or a list and the LISP interpreter automatically keeps track of the type of each variable's value.
In the above examples all the variables were being assigned numeric values but they can also be assigned the values of S-expressions. For instance, we may want to give the atom d, the value of another atom, x:
> (setq d x)LISP looks up the value of x and places it in the location, d. This corresponds nicely to the Pascal statement:
d := xNow, in Pascal, if you wrote:
d := 'x',Pascal would not attempt to look up the value of x. Pascal sees this as meaning the character x itself. The same situation in LISP is the following:
> (setq d 'x) xIn this case, the quote mark in front of the x tells LISP not to try to look up the value of x, but merely to take the symbol, x and put it into the location, d. So, if we ask LISP what d is, we get:
> d x
The other assignment function LISP has is called set and it evaluates both its first and second arguments, so assuming d now has the value x, the following statement will set x to 99:
> (set d 99) 99Thus, if we now look at the value of x, we find that it is 99:
> x 99Set therefore allows an extra level of generality that is not found in most conventional languages: the location where a value goes can itself be a variable.
If we want to let d have the symbolic value consisting of the list, (john loves mary), we can use set or setq as follows:
> (setq d '(john loves mary)) (john loves mary)
> (set 'd '(john loves mary)) (john loves mary)Here, the quote mark in front of the list, (john loves mary) prevents LISP from trying to evaluate the list. Without this quote mark, LISP would think of john as a function to evaluate and loves and mary as arguments that needed to be evaluated and then passed on to the function, john.
This notation using a single quote mark in front of something is actually a shorthand notation for the function, quote. Quote is a function that takes in its argument and sends back as its answer, the same value that went into it. The above examples using quote could have been written out in this long-hand fashion as follows:
(setq d (quote x)) (set (quote d) (quote x)) (setq d (quote (john loves mary))) (set (quote d) (quote (john loves mary)))
Another useful function, eval, can be used to evaluate its argument further. For instance we will give the atom, x, the value y and give y the value z:
> (setq x 'y) y
> (setq y 'z) zIf we ask for the value of x, we get:
> x yIf we ask for (eval x) we get:
> (eval x) z
We now want to look at another set of basic LISP function, the ones that make it possible to put together and tear apart S-expressions. We start first with cons, short for listcons tructor. In this example we can cons together two atoms a and b:
> (cons a b) (a . b)Obviously, cons forms a dotted pair with its arguments. The first argument of the cons ends up as the item on the left and the second arguments ends up as the item on the right. If we cons a and nil together we get:
> (cons a nil) (a)Likewise, if we have a list, (b c) and we want to produce a list with the atom a on the front of (b c) we type in:
> (cons 'a '(b c)) (a b c)Here are a couple of more examples of cons and its effects:
> (cons '(a b c) '(x y z)) ((a b c) x y z)
> (setq list1 '(x y z)) (x y z)
> (cons 'a list1) (a x y z)It is important to notice that in the last example, list1 was not changed when the atom, a, was consed with list1. List1 is still just the list, (x y z). Quite often people see an expression like:
(cons 'a list1)and expect that list1 is changed but to actually change the value of list1 would require the statement:
> (setq list1 (cons 'a list1))
A second important means of constructing S-expressions is to use append to run two lists together as in the following examples:
> (append '(a b c) '(x y z)) (a b c x y z)
> (append '(a b c) '(x y z) '(1 2 3)) (a b c x y z 1 2 3)Some LISPs allow append to have an arbitrary number of arguments while other LISPs limit the number of arguments to only two.
Another useful function is list that takes its arguments and puts them in a list. Here are two examples:
> (list 'x) (x)
> (list 'x (cons 'a (list 'b))) (x (a b))
The functions that tear lists apart have very unfortunate names, they are: car, that returns the first item in the list and cdr (pronounced could-er) that returns all but the first item in the list. These names come from the names of registers on one of the first computers to run LISP and LISPites have never felt a real need to replace them with sensible names like first and rest although some newer LISPs also have the functions first and rest in addition to car and cdr. Some examples of using car are the following:
> (car '(a b c)) a
> (car '((a b) (c d) (e f))) (a b)
> (car '((a b) c d)) (a b)
> (car '((a b c d (e f)))) (a b c d (e f))
Needless to say, trying to take the car of an atom is likely to provoke an error or produce some strange result. Exactly what will happen varies from LISP to LISP. Some examples of the use of cdr are these:
> (cdr '(a b c)) (b c)
> (cdr '((a b) (c d) (e f))) ((c d) (e f))
> (cdr '((a b) c d))) (c d)
> (cdr '((a b c d (e f)))) nilOf course, the cdr of an atom is likely to produce an error or a strange result as well.
Some LISPs have a last function last that will give the last item of a list in a list or the last atom in a dotted pair:
> (last '(a b c)) (c)
> (last '(a . (b . c))) c
To get to an item deeper within a tree, calls to car and cdr can naturally be nested, as in these calls:
> (car (cdr '(a b c))) b
> (car (cdr '(a (b c) d))) (b c)
> (car (cdr '((a b) c d))) c
> (car (car '((a b) c d))) a
> (cdr (cdr '((a b) c d))) (d)Reaching items within a list in the above fashion is awkward so LISPs have functions that combine the actions of cars and cdrs in just one function. For instance, the sequence, (car (cdr x)) can be replaced by (cadr x) and (cdr (car x)) can be replaced by (cdar x). The names are derived by taking the long version of the sequence of operations and extracting, from left to right, the middle letter and then putting a ``c" in front and an ``r" on the end. Here are some examples of these compound functions:
> (cadr '(a b c)) b
> (cadr '(a (b c) d)) (b c)
> (cdar '(((a b)(c d)) x y z)) ((c d))
> (caar '((a b) c d)) a
> (cddr '((a b) c d)) (d)Some LISPs carry this out to 3 or 4 cars and cdrs but even this organization can be awkward. Newer LISPs often have the nth function that returns the nth item in a list, counting the first item as item 0, as for example:
> (nth 3 '(a b c d e f)) d
> (nth 0 '(a b c)) a
> (nth 3 '(a b c)) nilAsking for an item beyond the end of the list returns nil.
The last basic function we will look at in this section is the LISP function to define functions. In most LISPs this function is called defun. Defun expects the first argument to be the name of the function and the second argument to be the list of parameters, which must be the empty list (nil) for functions with no arguments. The parameters are all value parameters. All the remaining S-expressions in the defun function call are statements that LISP evaluates when the function is called. The value calculated for the last statement in the function is the value that the function returns. Values cannot be returned through the arguments of the function but global variables can be set within a function. Here is the definition of a simple function, plus-ends, that adds together the first and last numbers in a list:
(defun plus-ends (x)
(+ (car x) (car (last x))))
The function is called like any other LISP function as in:
> (plus-ends '(1 2 3 4 5 6 7)) 8
There are many other points regarding functions and defining and using variables in functions that are quite important to know, but these fine points of functions and variables will be considered in a later section. We simply defined defun here so that some simple functions could be defined in the next few sections.
LISP13.2 Control Functions
In this section we will look at a few of the most useful and widely used functions for controlling execution but first we need to look at functions that test for various conditions. In doing tests, LISP functions will return the built-in constant, nil (or the empty list, ``()") for false and the built-in constant, t or some non-nil value for true.
Predicates are functions that return true or false (t or nil). Many, but not all LISP functions that are predicates have names ending in ``p". The first predicate we look at is called numberp which tests to see if its argument is a number. Here are some examples of the use of numberp:
> (numberp 9) t
> (numberp 'x) nil
> (numberp '(1 2 3)) nilThe predicate, atom, tests for atoms:
> (atom 1) t
> (atom 'x) t
> (atom '(+ x y)) nilThe predicate, listp (not to be confused with list), tests for non-atoms:
> (listp 1) nil
> (listp 'x) nil
> (listp '(+ x y)) t
> (listp (cons 'a 'b)) tThe function, boundp, checks to see if its argument has a value. Suppose, x does, but y does not. Here are some examples of boundp:
> (setq x 1) 1
> (boundp 'x) t
> (boundp 'y) nil
The function, =, tests for the equality of numbers but note that it does NOT test symbolic expressions correctly:
> (= 1 2) nil
> (= 2 (+ 1 1)) t
> (= '(b c) '(b c)) nilThe function, /=, tests for inequality of numbers but not lists and non-numeric atoms:
> (/= 1 2) t
> (/= '(b c) '(b c)) tIn addition, the functions, > , > = , < and < = can be used to test relationships between numbers:
> (> 8 9) nil
> (< 8 9) t
> (>= 9 8) t
> (<= 1 2) tThe function, equal, will correctly test for equality of numbers, lists and symbolic atoms:
> (equal 1 1) t
> (equal 1 2) nil
> (equal '(b c) '(b c)) t
> (equal 'a (car '(a b c))) tThe function, null, is the same as the function, not. They both invert true/false values:
> (null (= 1 2)) t
> (not (= 1 2)) t
> (null (equal 'a (car '(a b c)))) nil
LISP has functions to or and and together results. To show some examples we will first assign x, y and z some values:
> (setq x 1) 1
> (setq y 2) 2
> (setq z 3) 3
> (or (= x 1) (> z 0)) t
> (and(= x 1) (> z 0)) t
(and (= x 1) (= y 2) (< z 0)) nil
> (or (= x 2) (= y 14) (> z 0)) tThe and and or functions will take an arbitrary number of arguments. The or function checks the conditions in order until it finds one condition that is true. If it finds one, it will not go on to check any other conditions there may be and it returns as its value this non-nil value that it found. If none of its arguments are non-nil, or returns nil. The and function checks its arguments until the function succeeds by finding that all its arguments are non-nil, in which case it returns the value of its last argument, or if it finds an argument that is nil, it returns nil without checking any more arguments. In the above examples, we have been checking numerical relations, but remember that LISP's definitions for true and false, are non-nil and nil, so the following tests are valid as well:
> (and 'hello 'world) world
> (and '(hello world)) (hello world)
> (and nil '(hello world)) nil
> (or 'hello 'world) hello
> (or nil '(+ x y) nil) (+ x y)
The original and most common conditional function in LISP is the cond function. Its basic form is the following:
(cond ( <test 1> <answer 1> )
( <test 2> <answer 2> )
.
.
.
( <test n> <answer n> ))
Each argument of cond consists of a list where the first item in the
list is a test expression to evaluate and the second item is an answer
expression. Cond starts looking at its arguments one by one to try to
find a test that comes up non-nil and if it finds one it evaluates the
corresponding answer and returns that value for the cond. In case it
doesn't find a non-nil test expression, the cond returns nil. For an
example of cond we will first set a variable, x, to be the list,
(a b c). Then we type in a cond statement that looks for the atom
b in all three positions in the list. If it finds b in the
first position, it will return 1, otherwise if it finds b in the
second position, it will return 2, otherwise if it finds c in the
third position it returns 3 otherwise it returns nil. Here is the
sequence given to LISP together with its responses:
> (setq x '(a b c)) (a b c)
> (cond ((equal 'b (car x)) 1) > ((equal 'b (cadr x)) 2) > ((equal 'b (caddr x)) 3) > (t nil)) 2One extra item of note is the use of the built-in constant, t, that is always true, in the final test. The use of t as a test condition amounts to creating an ``otherwise" or ``default" clause, since t is always true.
Older LISPs only allow one S-expression for the answer portion but many newer LISPs allow more than one S-expression to be evaluated. In this case, the final S-expression becomes the value of the cond. Here is an example of this newer type of cond:
(cond ((equal x y) (print x) (+ x y))
(t (print x) (print y) (- x y)))
In this cond, if x equals y then x is printed and the sum, (+ x y)
is returned, otherwise x and y are printed and the difference, (- x
y) is calculated and becomes the value of the cond.
All LISPs will allow the test condition, if true, to be the value of the cond if there is no answer portion, as in:
> (cond ((cons 'a 'b))) (a . b)
For another example of the use of cond, here is the well known factorial function:
(defun fact (n) ; function definition
(cond ((equal n 0) 1) ; if n = 0 return 1
(t (* n (fact (- n 1)))))) ; otherwise recurse
Little needs to be said about this solution. If n is equal to 0
then the answer is 1 and 1 becomes the value of the cond. Since the
cond is the last expression in the function definition, the function
call returns this value. If n is not equal to 0, the cond will make a
recursive call to fact. Comments in LISP begin with a ``;" and continue
to the end of the line. One problem with this notation for comments is
that the comments get thrown away when a file of functions gets read in,
so if you list a function on the screen, to find out how it works you
won't get the comments. It is not hard to define a comment function
using defun (or maybe better yet a macro, using defmacro) that does
nothing but give a comment, then the comments won't be lost when the
function is read in.
In section 4.2 we gave definitions for a function member, that checks to see if a symbol is in a list. Most LISPs have the member function built-in, but here is a home-made definition of member, which we will call, mem, instead:
(defun mem (x l)
(cond ((null l) nil)
((equal x (car l)) t)
(t (mem x (cdr l)))))
Again the first argument, x, is the item to look for and l
is the list to look in. Here are some calls to mem:
> (mem 'b '(a b c)) t
> (mem 'd '(a b c)) nilThis LISP version of member is different from the PROLOG version in that it must start off with an explicit test as to whether or not the list to search is empty. If it is not empty, you can go on to do the other tests. If it is empty, you must explicitly return nil. So there are a couple of steps here that have to be explicitly written out, unlike PROLOG where the steps come automatically. The second test covers the case where the first value in l is equal to x. If this case is true, return t. The otherwise clause covers the case where x is not the first number in the list. In this last case, the answer to send back is then the answer as to whether or not x is in the cdr of l.
Here is the LISP version of the PROLOG predicate, pos, also defined in section 4.2 that returns a list of positive numbers in a list, l:
(defun pos (l)
(cond ((null l) nil)
((> (car l) 0) (cons (car l) (pos (cdr l))))
(t (pos (cdr l)))))
A possible call would be:
> (pos '(-1 44 97 -300 10)) (44 97 10)This LISP version is even closer to the PROLOG version. The first test returns nil if the list is empty. The second test checks to see if the first number, (car l) is greater than zero. If it is, then the result to send back is the number consed onto whatever positive numbers there are in the rest of the list. These other numbers are found by calling pos with the cdr of l. The otherwise clause covers the case where the first number is not positive. It says that the list of positive numbers in the list is the list of positive numbers in the rest of the list.
We are now going to go and look at functions that can be used to do iteration and the problem of making a list of all the positive numbers in a given list will be used to illustrate the methods. The first function to allow looping in LISP was the prog (short for program) function and it allows for labels and gotos within the function. Of course, it dates back to the time before people realized that goto statements were the work of the Devil. The following is an outline of a prog function:
(prog (<a list of variables>)
<function call or label>
<function call or label>
.
.
.
<function call or label>)
The first argument is a list of variables that the prog will use. If
there are no variables needed, this first argument should be nil. Any
variables that are listed are initialized to nil but newer LISPs allow
variables to be initialized to specific values. These variables are
destroyed when the prog finishes. Here is an example of a version of
pos, called iter-pos-prog, that uses a prog with a label and goto
statement:
(defun iter-pos-prog (l)
(prog (first positives)
loop
(cond ((null l) (return positives)))
(setq first (car l))
(cond ((> first 0)
(setq positives (cons first positives))))
(setq l (cdr l))
(go loop)))
A call to this function and its result is:
> (iter-pos-prog '(-1 44 97 -300 10)) (10 97 44)As to how the prog works, when the prog is entered, the variables, first and positives are created and set to nil. LISP passes right by the identifier, loop, that is being used as a label. This is just an arbitrary name, but it is a commonly used one for labels within a prog. Following the label, the cond checks to see if the list of numbers to check, l, is empty. If it is, then the corresponding return function evaluates its argument and lets that be the value of the prog. If the list isn't empty, then we let the variable, first, be the first item in the list. The following call to cond checks to see if first is greater than 0. If it is, positives is changed to a new value with the value of first consed onto the current list of positives. Then this first item is removed from the list, l, making the list shorter. The go function sends the interpreter to the statement after the label, loop.
The above way of looping is really quite awkward and prog should be avoided except when it is absolutely necessary. LISP provides a neater way of performing the same operation on a list of numbers, using the mapcar function. Mapcar's first argument is the function to compute and its second argument is the list of items to work on. Mapcar takes the first item from the list, computes the function value and places this new value at the start of an answer list. Then mapcar moves on to compute the function value of the second item in the list. This result is added to the end of the answer list, and so on. Here is a LISP function that uses mapcar to do the pos problem:
(defun iter-pos-mapcar (l)
(mapcar 'positive l))
Of course, we still need to define the function, positive:
(defun positive (x)
(cond ((> x 0) x)
(t nil)))
Here is a sample call of iter-pos-mapcar:
> (iter-pos-mapcar '(-1 44 97 -300 10)) (nil 44 97 nil 10)Unfortunately, the list contains the atom nil for negative numbers, so this is not yet quite right, however it is quite easy to write another function that will strain out the nils. Some LISPs have a function, mapc that works just like mapcar, except it will strain out nil values from the answer list.
Another iterating function found in more modern LISPs is, dolist. The syntax of dolist is as follows:
(dolist (<variable> <list> <result>)
(executable statement)
(executable statement)
.
.
.
(executable statement))
When dolist begins, the variable is set to the first value in list. The
statements are then executed and LISP sets the variable to the second
item in the list, and the statements are executed again. This cycle
continues until there are no more items in list. < result > is then
the value returned by the call to dolist. Here is an example of dolist
to do the pos problem again and also a call of the function:
(defun iter-pos-dolist (l)
(setq positives nil)
(dolist (x l positives)
(cond ((> x 0)
(setq positives (cons x positives))))))
> (iter-pos-dolist '(-1 44 97 -300 10)) (10 97 44)Notice that in this case, when the setq statement sets positives to nil, it will create a new global variable, positives.
Newer LISPs have many other control functions as well, including an if-then-else function and many other looping functions.
LISP13.3 Input, Output, Strings and Properties
This section covers input and output functions, string manipulation functions and property list functions.
A couple of print statements appeared in the last section. The print function simply prints out its one argument and then writes an end of line marker. To print out an item without writing an end-of-line marker, the function, prin1 is used. The function, terpri will write an end-of-line marker. Here is a function called, dummy that simply writes out its three parameters on one line:
(defun dummy (x y z)
(prin1 x)
(prin1 y)
(prin1 z)
(terpri))
The following is a call to dummy, and its result:
> (dummy 1 2 'hello) 12hello nilThe value returned by terpri is nil and so the value of dummy is nil. In addition to print and prin1, princ will print a single character or a character string. In this case printc prints a single blank:
(princ " ")Princ is like prin1 in that it does not write an end-of-line marker. LISPs that have string handling capabilities probably allow print and prin1 to print out strings as well so in many LISPs there is no need for princ.
Constructing and printing an output expression can often be awkward. For instance, you may want to print out a message together with the value of a variable all in one list, such as:
(x is 1)One way to do this is to write:
(print (append '(x is) (list x)))There is a convenient function, called backquote, that can make the process a little easier. The short-hand for calling the function, backquote is to use the backquote character, ```", in the same way you would use ``'" as a short-hand for quote. Backquote functions like quote, but with two exceptions. The first exception is that an item in the list immediately preceded by a comma is evaluated:
(print `(x is ,x))This call to print then produces the string, (x is 1). The comma is also treated internally as a function called, comma. A second convenience that can be used within backquote is a comma followed by an at sign, ``,@". The item after this pair should be a list that gets spliced into the backquoted one. For example let m be the list defined like so:
> (setq m '(a list into a list)) (a list into a list)Typing in ,@m, in the middle of a backquoted expression fits m into the list, as in:
> (print `(the comma-at function splices ,@m)) (the comma-at function splices a list into a list) (the comma-at function splices a list into a list)This backquote feature is common in newer LISPs but not in older ones. The backquote function does not need to be used just within the print function, it can be used anywhere, but it is most often found within print.
For all the printing functions there is an optional extra parameter, a pointer to the file to print on. Naturally the default is the terminal output file. To create a file pointer to some other file, say, outfile, the function openo is called as shown in this example where two lines are printed to outfile:
> (setq out-file-ptr (openo "outfile")) #<File: #a2d68>
> (print 'hello out-file-ptr) hello
> (print 'world out-file-ptr) worldTo close the file, the function close is called with the file pointer:
> (close out-file-ptr) nilThe file outfile, now contains the two lines:
hello world
The read function reads an S-expression from the input file and produces a prompt. In the following case, the user types in the list, (hello world) at the second prompt and then the read function call returns the value (hello world), which prints out as the value of the call:
> (read) > (hello world) (hello world)Another function, read-char, will read a single character. If an argument to read or read-char is present, it is assumed to be a file pointer. Files are opened for input using the function, openi and the filename is enclosed in double quotation marks:
> (setq in-file (openi "outfile")) #<File: #a2d68>
> (read in-file) hello
> (read in-file) world
> (read in-file) nilWhen end-of-file is reached, nil is returned. Again, the function, close, is necessary to close a file.
Some other useful functions are explode, that takes an atom and converts it to a list of characters, or really the numeric ASCII codes for the characters:
> (explode 'hello) (104 101 108 108 111)Implode takes in a list of the ASCII codes for characters and fuses them into a single symbol:
> (implode '(104 101 108 108 111)) hello
Many LISPs have character manipulation functions. For example, here is a demonstration of how the string concatenation function, strcat, can be used:
> (setq x "hello") "hello"
> (setq y " world") " world"
> (strcat x y) "hello world"
The function, chr converts the ASCII code for a single character to that character:
> (chr 104) "h"Strlen will find the length of a string:
> (strlen "hello") 5The function, itoa, for integer to ASCII, takes in an integer and produces a character string:
> (itoa 104) "104"The function, atoi, for ASCII to integer, takes a string and converts it to an integer:
> (atoi "137") 137
Another important feature of LISP is that in addition to an atom having a value, an atom can also have a number of other properties. Early versions of LISP had the put (or putprop) function to assign properties and the get function to look up properties. Newer versions of LISP use the setf function to assign properties and won't necessarily have the put function. It is easy to define put using setf, however. First, here is a summary of put and its arguments:
(put property atom-name value)And here are some calls to put to give some atoms some properties:
> (put 'size 'man 'large) large
> (put 'size 'boy 'medium) medium
> (put 'texture 'man 'soft) soft
> (put 'texture 'rock 'hard) hardThe function get will return the property value of an atom. These are some examples of get:
> (get 'rock 'texture) hard
> (get 'boy 'size) mediumProperties can be removed by using the remprop function:
> (remprop 'boy 'size) nil
> (get 'boy 'size) nilThe use of setf for storing properties is rather strange. As an example of its use, here is a call to setf inside a home-made version of put:
(defun put (property atom-name value)
(setf (get atom-name property) value))
Setf has many other uses as well, but we will not discuss them.
LISP13.4 Advanced Functions and Macros
In this section, we will look at more features of standard functions as well as macros, another type of function. First we will consider the problem of declaring variables within a function and the problem of what variables can be accessed at a given time. This is quite a problem because there are two ways of treating variables. In older LISPs, such as XLISP 1.4, a strategy of dynamic scoping was used while most newer LISPs, such as XLISP 1.6, follow the COMMON LISP approach of using static (or lexical) scoping.
The first point we look at will be the let and let* functions that create variables. Let and let* are only found in the newer LISPs. Let and let* can be used anywhere within a LISP function but they are most commonly seen at the beginning of a function. Effectively they are used to declare extra variables to be used within the function and they vanish when the function ends. The structure of let and let* are:
(let* ((<variable 1> <initial value>)
(<variable 2> <initial value>)
.
.
.
(<variable n> <initial value>))
(<executable statement>)
(<executable statement>)
.
.
.
(<executable statement>))
The difference between let and let* is best described by using two small
functions that are identical, except that one uses let and the other
uses let*. Here is the first function, dummy-with-let:
(defun dummy-with-let (a)
(let ((x a)
(y x))
(print '(inside dummy-with-let))
(print `(x is ,x))
(print `(y is ,y))))
This function doesn't do anything special, it merely prints out a little
message and the value of x and the value of y. When the let is entered,
the variable x is assigned the value a but because the let function
doesn't look at any of the assignments it has made so far, y will be
assigned whatever value it had before the local x was assigned the value
a. For instance, we can set up a global variable, x and set it to 99:
> (setq x 99) 99A call to dummy-with-let will then make y be the value, 99. Here is a call to dummy-with-let and the results it produces:
> (dummy-with-let 1) (inside dummy-with-let) (x is 1) (y is 99) (y is 99)On the other hand, let* does know about the assignments it has made, so the following function, dummy-with-let* gives y the same value as x:
(defun dummy-with-let* (a)
(let* ((x a)
(y x))
(print '(inside dummy-with-let*))
(print '(x is ,x))
(print '(y is ,y))))
> x 99
> (dummy-with-let* 1) (inside dummy-with-let*) (x is 1) (y is 1) (y is 1)
A big difference between the various versions of LISP has to do with what variables are accessible from what functions. Newer LISPs only allow a user to access global variables and the variables within the scope of the block in which the variable is declared. This corresponds to the way Pascal works. This scheme is known as lexical scoping and the newer LISPs, such as XLISP 1.6 work this way. Older LISPs, such as XLISP 1.4 use dynamic scoping to look up variables. In this older method, every variable is kept on a run-time stack, together with its name, then, when a variable is needed, LISP starts at the top of the stack and finds the first variable with that name and returns its value. LISP programmers that are not used to this unusual scheme will therefore occasionally run up against really strange errors.
To illustrate the differences between the two methods, here are two simple functions, scope1 and scope2 that don't do anything special:
(defun scope1 (a b)
(let ((x a)
(y b))
(print '(inside scope1))
(print (append '(x is) (list x)))
(print (append '(y is) (list y)))
(scope2 (+ a b))))
(defun scope2 (c)
(print '(inside scope2))
(print (append '(x is) (list x)))
(print (append '(y is) (list y))))
Scope1 prints out the values of x and y and then calls scope2. Here
is what happens with dynamic scoping:
> (scope1 1 2) (inside scope1) (x is 1) (y is 2) (inside scope2) (x is 1) (y is 2) (y is 2)On the other hand, here is what happens with lexical scoping:
> (scope1 1 2) (inside scope1) (x is 1) (y is 2) (inside scope2) error: unbound variable - x
The kind of functions we have been creating with defun all evaluate their arguments before they execute. Older LISPs refer to the type of function that evaluates its arguments as an expr and a function that does not evaluate its arguments is called a fexpr . Newer LISPs don't have fexpr's but they have the defmacro function that creates a function that acts like a fexpr in that it does not evaluate its arguments, but then in addition, whatever a macro finds as its answer is evaluated again in a variable environment that is independent of the macro.
The first feature of the macro definition we will show is how the macro computes its value. First, here is a function, called add-function, that takes in two parameters and forms a list with the atom, +, at the start followed by its two parameters:
> (defun add-function (x y) (list '+ x y)) add-function > (add-function 3 4) (+ 3 4)Of course, the result is as expected. Now we will define a macro called add-macro that is otherwise identical to add-function:
(defmacro add-macro (x y) (list '+ x y))Now if we call add-macro with the parameters 3 and 4, it will form the list, (+ 3 4) and then LISP will go on to evaluate it:
> (add-macro 3 4) 7
The next couple of features to illustrate will be how arguments to macros are not evaluated and how the macro result is evaluated in an environment outside of the macro. To do the illustration, we will use a macro, add-macro2, that is much the same as add-macro:
(defmacro add-macro2 (p1 p2)
(let* ((x 1)
(y 2))
(print p1)
(print p2)
(list '+ p1 p2)))
The only differences are that we will have an x and y inside the
let* and the two parameters, p1 and p2 will be printed out when the
macro executes. We will set up global variables x and y to be 7 and
8 respectively:
> (setq x 7) 7
> (setq y 8) 8We now call add-macro2 with x and y as parameters:
> (add-macro2 x y) x y 15The first thing to notice about the output is that p1 and p2 have the values x and y and not 7 and 8. Of course, this is because macros don't evaluate their arguments. As the function executes, the x within the let* is set to 1 and the y within the let* is set to 2. Then, the expression, (+ x y) is constructed and becomes the value of the let*. The variables x and y within the let* vanish and the parameters, p1 and p2 also vanish. Now, the expression, (+ x y) is evaluated, giving a value of 15. It is easy to look at the last statement in a macro and think that it will know about variables in the macro. We made this special demonstration to emphasize the fact that the final expression created by the macro is not evaluated within the macro.
The final feature of functions and macros has to do with the fact that they can have optional parameters or even an arbitrary number of parameters. A nice instance of when optional parameters come in handy is, if you wrote your own LISP pretty-printing function, called, say pp. On most occasions, you probably want the function pretty-printed on the screen, so a call like, (pp fact) is convenient. On the other hand, there may be occasions when pretty-printing a function to a different file is necessary. On those occasions, you want to specify the file pointer as a second argument so a definition for pp would start out as:
(defmacro pp (item &optional where)
(let* ((fptr (cond (null where) *standard-output*)
(t (openo ...
The &optional keyword flags where as an optional parameter. If there
is no second parameter in a call, where will be nil. In the let*, fptr,
the file pointer is either set to the file pointer, *standard-output* if
where is nil or otherwise, to some other file pointer created by openo.
Another way to get an arbitrary number of parameters is to use the keyword, &rest, followed by the name of the variable that gets the parameters as in:
(defmacro comment (&rest c) t)Whatever the macro is called with, it is all put in the list, c, and it is up to the programmer to break off items from the list, as necessary. This comment macro doesn't do any calculation and it just sends back the value, t. With this macro, arbitrary long comments can be inserted in LISP code, as in:
(comment With the comment macro, comments won't be lost when
they are read in)
Note, though that there will be a penalty in the execution time of a
function containing this type of comment.
LISP13.5 A Few Examples
In this section we will finish discussing LISP by looking at a few examples of common problems done in LISP: substitution of expressions in a tree, quicksort and a matching problem that is similar to PROLOG matching.
The first function to look at is the substitution into a tree function. Most LISPs already have a built-in substitution function called, subst but we will write our own, called sub. Sub will search through its first argument, a tree, for instances of its second argument, old. If it finds an instance of old, it replaces it with a new expression, given in the third argument of sub. For example:
> (sub '(a b (c d a) b) 'b 'x) (a x (c d a) x)
> (sub '((a b) (c d)) '(a b) '(a b c d)) ((a b c d) (c d))The function to do this is straightforward:
(defun sub (tree old new)
(cond ((null tree) nil)
((equal tree old) new)
((atom tree) tree)
(t (cons (sub (car tree) old new)
(sub (cdr tree) old new)))))
For the first test, if the tree is nil then return nil. The second test
looks at the whole tree to see if it is equal to the expression to
replace. If it is, then it is replaced by the new expression. The
third test is to see if the tree is just a single atom (that won't be
equal to the old expression) and if it is an atom, return that atom.
The otherwise clause simply forms an answer where the answer is the new
tree formed by substituting into the car of the tree and then consing
this with the new tree formed by substituting into the cdr of the tree.
The next example to look at will be quicksort. Recall that the algorithm works as follows. First select a number, called the key, possibly the first number in the list and use it to split the list into two separate lists, one called left that will have all the values less than or equal to key and one called right that will have all the numbers greater than key. For instance, given the list:
(19 5 23 17 89 0 10),it would be split into the two lists:
|
|
(0 5 17 19 23 89 101)
Here is the LISP definition of quicksort:
(defun qs (l)
(let* ((twolists nil)
(left nil)
(right nil)
(sortedleft nil)
(sortedright nil))
(cond ((null l) nil)
(t (setq twolists (partition (car l) (cdr l)))
(setq left (car twolists))
(setq right (cdr twolists))
(setq sortedleft (qs left))
(setq sortedright (qs right))
(append sortedleft
(cons (car l) sortedright))))))
The trivial condition in the process is to note that the sorted
version of an empty list is the empty list. The second condition
does the real work. The first problem is to split the list, l,
into two portions, left and right. The number that splits the list
will be the first item in l, or (car l). Obviously the list l could be
split by first calling one function to return all the numbers less than
or equal to (car l) and then calling a second function to return all the
numbers greater than (car l) but this version does not work that way.
Instead just one function call is made to a function called, partition.
Partition will have to return two lists. To do this, partition
will take the two lists and cons them together to form just one
value to return. This list will be saved in the variable, twolists.
So if the initial list to sort was (19 5 23 17 89 0 101) then
calling partition will produce:
> (partition 19 '(5 23 17 89 0 101)) ((0 17 5) 101 89 23)In the next steps, left will get the first part of this list and right will get the rest. The function qs will then get the list, left, and produce the list, sortedleft. A second call to qs with right will produce the list, sortedright. In the last step the pieces are put together.
There is still the matter of looking at how to partition the numbers into two lists in just one call. The definition of partition and a function it uses called partition2 are as follows:
(defun partition (key l) (partition2 key l nil nil))
(defun partition2 (key l left right)
(cond ((null l) (cons left right))
(t (cond ((> (car l) key)
(partition2 key (cdr l) left
(cons (car l) right)))
(t (partition2 key (cdr l)
(cons (car l) left)
right))))))
The function partition itself, does little, it merely sets up a call to
another function, partition2, where the real work is done. The first
parameter of partition2 is the key used to divide the list, l, the
second parameter. The third and fourth parameters function as
accumulating parameters . In each recursive call of partition2,
the first number in l is taken off and added to either the front of
the third parameter, left, or the front of the fourth parameter, right.
At the beginning of the process, the variables will be:
key = 19 l = (5 23 17 89 0 101) left = () right = ()The function will find that the first number of l should be added to the left hand list. In the next call of partition, the variables will be:
key = 19 l = (23 17 89 0 101) left = (5) right = ()In each recursive call the first number in l will be added to one list or the other. Finally, l will be empty and the result sent back will be left consed onto right.
The final example we will look at in this section is a LISP matching function that does a simple version of PROLOG-like pattern matching. We will assume that there is one list that contains a pattern, possibly including variables, while a second list is a fact that never has any variables in it. With this restriction, the simple matcher will not be able to handle rules. We will call the pattern matching function, match. Here are a few sample calls to match, and the values that are returned:
> (match '(likes john X) '(likes john mary)) ((X mary))
> (match '(likes X Y) '(likes bob cardinals)) ((Y cardinals) (X bob))
> (match '(likes bob cardinals) '(likes bob cardinals)) t
> (match '(likes bob cubs) '(likes bob cardinals)) nilAs can be seen, the pattern is the first argument and the data is the second argument. Variables, as in PROLOG will start with a capital letter. When the two lists match, a list is returned that contains variables and their values. If there are no variables and the lists match, t is returned. If the patterns don't match, nil is returned.
In programming this function, two problems will immediately come to mind. The first problem is that we need a way to identify a variable and the following function will do this:
(defun variable (x)
(let* ((firstch (car (explode x))))
(cond ((and (>= firstch 65)
(<= firstch 91))
t)
(t nil))))
This function works by taking its variable, x, exploding it into a list
of ASCII characters and examining the first one. If it falls in the
range, 65 to 91, it is a capital letter so return t, otherwise return
nil.
The second problem that comes to mind is that we will need to keep a list of variables and their values. A list that keeps variables and their values is known as an association list . The values returned in the above examples show the association lists that the matching function created. Many LISPs have built-in functions for this problem, but creating a list and a function to search it is quite easy so we will do without using the built-in functions. The structure of the association list will look like:
((<variable 1> <value 1>)
(<variable 2> <value 2>)
.
.
.
(<variable n> <value n>))
The function that searches the association list for a variable and
returns its value, will be called, val. Here is its definition:
(defun val (x a)
(cond ((null a) nil)
((equal (caar a) x) (car (cdar a)))
(t (val x (cdr a)))))
The item to search for is x and the association list is a. This
function follows the typical recursive pattern. The first item on the
list is checked to see if it is the variable-value pair we are looking
for and if it is, the value is returned. If the first item on the
association list is not what we're looking for, val searches the rest of
the list by passing the cdr of a on to another call of val. When the
list, a, is nil in a call to val, then nil is returned and the recursion
stops.
With the functions variable and val at hand, we can go on to the major part of the problem, the function match. The problem will really be divided into two functions, match and match2. Here is the definition of match:
(defun match (p d)
(cond ((equal (length p) (length d))
(match2 p d nil))
(t nil)))
First, the function, match will make a simple test to see if the pattern
list, p, and the data list, d, are the same length. If they are the
problem is passed on to match2. Match2 has a third argument that is
the association list. Naturally it must start out empty and
this call to match2 supplies this empty list.
Match2 is rather more complicated. Its arguments are the pattern, the data and the association list. Here is the definition of match2:
(defun match2 (p d a)
(cond ((null p)
(cond ((null a) t)
(t a)))
((equal (car p) (car d)) (match2 (cdr p) (cdr d) a))
((and (variable (car p)) (null (val (car p) a)))
(match2 (cdr p)
(cdr d)
(cons (list (car p) (car d)) a)))
((and (variable (car p))
(equal (val (car p) a) (car d)))
(match2 (cdr p) (cdr d) a))
(t nil)))
Match2 follows the standard pattern for recursive functions. It deals
with the first items in the lists p and d. If the tests on these
succeed, match2 is called with the cdrs of p and d. If p (and
therefore, also, d) become null, then every item in the two original
lists must have matched. We will now look at this general scheme in
more detail.
The first condition to check is whether or not p has anything left in it. We could just as well have checked d and if we hadn't put the length check into the function match, we would have to check to see if both p and d were null to detect a successful match. If match2 finds p is nil, we have to check if there are instantiated variables in the association list. If there are, this association list is sent back otherwise then t is sent back.
The second test in the cond is fairly simple:
((equal (car p) (car d)) (match2 (cdr p) (cdr d) a))This test checks the first atom in p against the first atom in d. If they match, then the problem becomes whether or not the rest of the lists, p and d match. This problem is passed on to another call of match2 using the same association list. For example, suppose the function call started out with:
p = (likes john X) d = (likes john mary)Then the two likes match and the problem becomes, in the next recursive call of match:
p = (john X) d = (john mary).The third test is more complicated:
((and (variable (car p)) (null (val (car p) a)))
(match2 (cdr p)
(cdr d)
(cons (list (car p) (car d)) a)))
If the atom at the start of the pattern, p, is a variable and val
reports that this variable isn't in the association list yet, then
obviously the variable can match whatever item is on the front of the
data list. The variable and its value will get added to the association
list. For example, if we were working on the problem:
(match '(likes X Y) '(likes bob cardinals))and we had progressed in the problem to the point where:
p = (Y) d = (cardinals)then the association list coming into this call of match2 would be:
a = ((X bob)).The atom, cardinals will match with Y. The list, (Y cardinals) will be formed and consed onto a so the next call of match2 will get:
a = ((Y cardinals) (X bob))Again, the question as to whether or not p and d match becomes the question as to whether or not the cdrs of p and d match and this problem is passed on to match2.
The last major test covers the case where the variable already has a value:
((and (variable (car p)) (equal (val (car p) a) (car d)))
(match2 (cdr p) (cdr d) a))
In this case, val returns the value of the variable and if this
value is the same as (car d), then the match succeeds. The rest of
the problem is passed on to match2, but there is no need to put
another entry on the association list. This test comes into use
for instance, in the call:
(match '(likes X X) '(likes john mary))Suppose the matching has progressed to the point where:
p = (X) d = (mary) a = (X john)This fourth test will take the X from p and check to see if it is a variable. It is, so LISP moves on to val to look up its value. Val returns, john. John does not match mary so the match fails. If, on the other hand, d was (john), then the X in p will match john and the matching process will continue.
If any of the four tests fail, then the whole match fails and the function returns nil. An otherwise clause at the end of the cond makes this explicit.
Some extensions to this problem to make a LISP program somewhat like a PROLOG interpreter are suggested in the exercises. A word of advice to the reader: if you plan on doing some of the exercises in this book using LISP, it is not necessary to write a PROLOG-like interpreter in LISP first. It is far easier to just produce a LISP program specific to the task at hand.
LISP12.6 Exercises
| 13.1. |
(a b (c d)) ((a b (c d))) ((a (b c) d)) ((a b (c d) (e f)) (g)))
| 13.2. |
| 13.3. |
| 13.4. |
| 13.5. |
| 13.6. |
> (nodupl '(h e l l o w o r l d))should give:
(h e l o w r d)
| 13.7. |
(sqq a 100 b 200 c 300 d z)sqq should set a to 100, b to 200, c to 300 and d to (quote z). Second write another macro, squ for ``set quoted unquoted" that will do the same except this time the call:
(squ a 100 c 300 d z)will set a to 100, c to 300 and d to the current value of z. Third write another macro, suu for ``set unquoted unquoted" that will do the same except this time the call:
(suu a 100 d z)will have to look up the value of a and set it to 100 and look up the value of d and set it to z.
| 13.8. |
(cons 'a l)and expect l to change, but of course, it does not. LISP produces a copy of l, puts the atom on the front of the copy and returns this answer without changing l so the above expression is really comparable to writing 1 + x in standard languages. Write a macro called gluon, that will change the value of its second argument so, for instance, if l is (b c), then (gluon 'a l) will give l the new value, (a b c).
| 13.9. |
| 13.10. |
a)Write a LISP function that will search a binary search tree for a given number. Naturally you will take advantage of the order within the tree to do the search quickly.
b)Write a LISP function to insert numbers into a binary search tree.
c)Write a LISP function to delete a number from a binary search tree.
| 13.11. |
| 13.12. |
a)When PROLOG is given a question it goes and searches through a whole database of facts whereas the match function in the last section only attempts to match one question against one piece of data. Write some extra LISP functions that will search a whole database of facts, then when the program finds an answer, it should print out the values of the instantiated variables, like PROLOG, and then wait for a response from the user. If the user types a ``;", the search for matches should continue, otherwise, let the matching process end.
b)The function, match, is not capable of handling rules. Modify it and/or create more functions so that it has this capability. A simple version of this could deal with just a short rule, like:
likes(X,lemonade) :- likes(X,yankees).
or you may want to program a slightly more complex version that
handles more than one clause to the right of the ``:-" operator. Choose
whatever input notation for the rules that you feel like. In a simple
version, a rule could be input as:
(:- (likes (X lemonade)) (likes (X yankees)))
or if you are more ambitious have your program input actual
PROLOG text.
| 13.13. |
(defun deriv (f var)
(cond ((and (atom f)
(equal f var) 1))
((atom f) 0)
((equal (car f) '+)
(list '+
(deriv (cadr f) var)
(deriv (car (cddr f)) var)))))
The first argument is the function to take the derivative of and the
second argument specifies what the variable is. These are some sample
calls of deriv:
> (deriv 'c 'x) 0
> (deriv 'x 'x) 1
> (deriv '(+ 1 x) 'x) (+ 0 1)
> (deriv '(+ x x) 'x) (+ 1 1)Have your program do derivatives for the following functions, where c is a constant and u and v are functions or variables:
|
1For this reason, some people believe that the actual origin of the name, LISP comes from ``Lots of Irritating Single Parentheses".
2Some function evaluate all their arguments while another type of function called a macro never evaluates its arguments and then there are functions like setq, described below that evaluates only one of its arguments. LISP programmers simply have to know how each function treats its arguments.